Introduction
The rise of large language models (LLMs) like ChatGPT, Claude, and Gemini has transformed the AI landscape. But behind these innovations lies a single fundamental breakthrough: Transformers.
Originally introduced in the groundbreaking 2017 paper Attention Is All You Need, Transformers have since revolutionized natural language processing (NLP), speech recognition, and even computer vision. But what makes them so powerful?
In this article, we’ll break down how Transformers work, why they’re efficient, and why they have become the backbone of modern AI. More importantly, we’ll develop an intuitive, visual understanding of the math behind the magic.
What Makes Transformers Special?
Before Transformers, many NLP models processed text sequentially, like humans reading a book. However, this sequential processing limited parallelization and made it computationally expensive to train large models.
Transformers changed the game by introducing self-attention, which allows words in a sentence to interact in parallel rather than sequentially. This not only improves efficiency but also enables models to capture complex relationships between words, even if they are far apart in a sentence.
How Do Transformers Predict Text?
At their core, Transformers are prediction machines. They analyze input text and assign probabilities to what comes next.
For example, if we give the model the sentence:
Today, the most influential thinker of all time was
The Transformer doesn’t just predict one answer; it assigns probabilities to many possibilities:
- Einstein (40%)
- Newton (30%)
- Plato (20%)
- Shakespeare (10%)
By sampling from these probabilities, the model generates diverse and natural responses. If it always picked the most likely option, responses would be predictable and robotic. Introducing randomness (through a parameter called temperature) adds creativity and variation.
Tokenization: Why Not Use Characters Instead?
Transformers don’t read raw text. Instead, they tokenize input into subwords, words, or punctuation marks—called tokens.
Why not just break text into characters?
While this seems logical, using characters would:
Increase sequence length exponentially.
Make training more expensive.
Prevent the model from quickly capturing word meanings.
Instead, tokenization balances efficiency and meaning by using subwords. For example:
- “unbelievable” → [“un”, “believable”]
- “running” → [“run”, “ning”]
This helps Transformers process words more efficiently while still capturing context.
Embeddings: Turning Words into Numbers
Computers don’t understand words—they understand numbers.
Each token in a Transformer is mapped to a high-dimensional vector. These vectors capture relationships between words in a way that preserves meaning.
For example, in a well-trained model:
- King – Man + Woman ≈ Queen
- Paris – France + Italy ≈ Rome
Words with similar meanings cluster together, and directions in vector space capture relationships like gender, nationality, and synonyms.

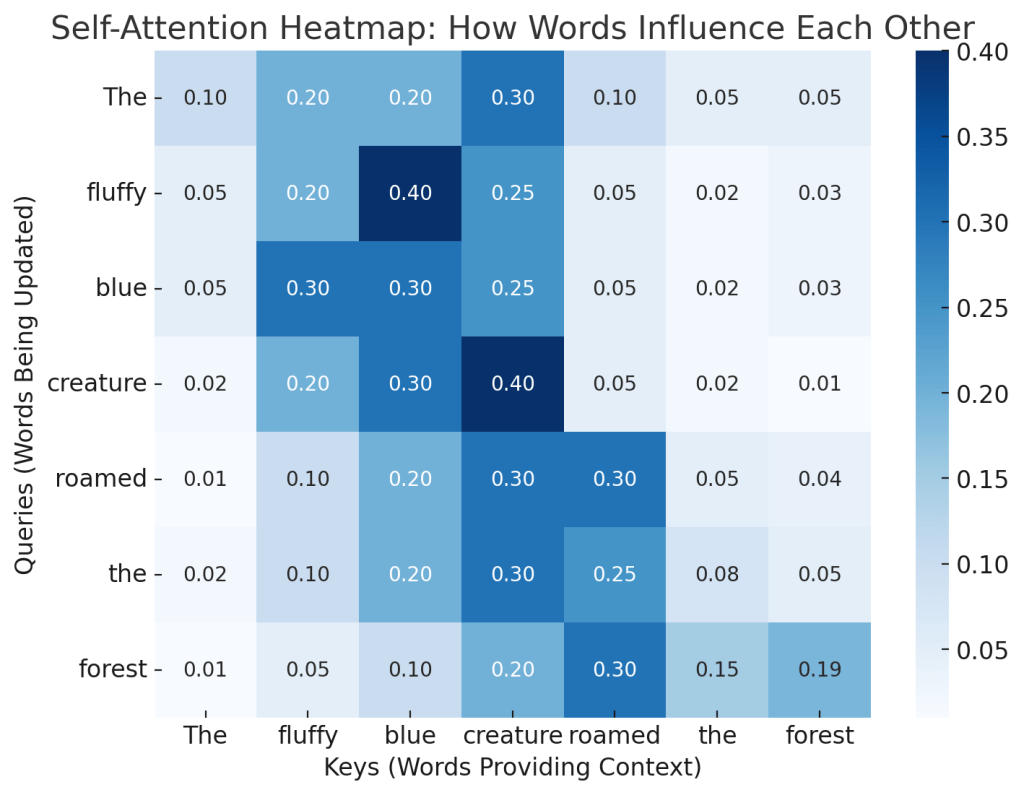
Self-Attention: How Words “Talk” to Each Other
The heart of Transformers is the self-attention mechanism. This allows words to interact and share information across a sentence.
For example, consider the sentence:
The fluffy blue creature roamed the green forest.
Before self-attention, each word is treated independently. The word “creature” doesn’t yet “know” that it is fluffy and blue.
How does self-attention work?
1️⃣ Query (Q): Each word asks a question (e.g., “Am I being described?”).
2️⃣ Key (K): Each word provides an answer (e.g., “Yes, I am an adjective.”).
3️⃣ Value (V): Each word shares relevant information (e.g., “Here’s my descriptive meaning.”).
The model takes dot products between queries and keys to determine which words should influence each other. This forms a weighted attention pattern, ensuring that adjectives modify the correct nouns.
The more relevant two words are, the stronger their attention score.
Why Are Transformers So Efficient?
1️⃣ Parallelization
- Instead of reading sequentially like older models, Transformers process entire sentences at once.
- This makes them highly parallelizable on GPUs, reducing training time.
2️⃣ Scalability
- More data + bigger models = better performance.
- Scaling up leads to qualitative improvements, making models smarter, not just bigger.
3️⃣ Multi-Head Attention
- Instead of using one attention mechanism, Transformers use many heads in parallel.
- Each head captures different relationships, improving understanding.
4️⃣ Masked Attention for Training
- During training, future words are masked so the model can’t cheat.
- This forces it to truly learn patterns rather than memorizing.
Beyond Text: How Transformers Work for Images
Transformers aren’t just for words—they process images, audio, and multimodal data too.
For images, patches of pixels act as tokens, and attention mechanisms help pixels “talk” to each other. This allows vision Transformers (like DALL·E and Stable Diffusion) to generate high-quality images.
Challenges & Future of Transformers
High Computational Cost
- Training large models requires massive GPU resources.
- New architectures (e.g., Mixture of Experts, sparse attention) aim to make them more efficient.
Interpretability
- We still don’t fully understand how Transformers store and retrieve knowledge.
- Interpretability research is working to uncover how models encode concepts.
Scaling Limits
- Attention computation grows quadratically with sequence length.
- New methods like long-context Transformers (GPT-4 Turbo) aim to fix this.
Final Thoughts: Why Transformers Matter
Transformers have redefined AI. Their self-attention mechanism, scalability, and parallelization make them the foundation of modern machine learning.
As research continues, we can expect even more efficient models capable of handling larger contexts, reducing energy consumption, and becoming even more human-like in reasoning.
One thing is clear: Transformers aren’t just an AI breakthrough—they are the future of intelligence itself.

Leave a comment